
生成AIだけを使って、予測AIを作ってみた話
生成AIの技術進歩がすばらしい。
Chat-GPTが公開されたのは2022年12月で、あれからまだ2年半ほどしかたっていない。しかし使用実感としてはもう当時とは比べ物にならないほどだ。
今回の記事では「AIでAIを作る」ことがどのくらい現実的になってきたのか知るために、生成AIだけを使って予測モデルを作ってみることにした。
- 生成AIで予測モデルを作成できるのか?
- コードを書かずともコピペでAIは作れる時代なのか?
さっそく試してみよう。
目次
生成AIでKaggleに提出できる予測モデルを作ってみた
さて、それでは生成AIに予測モデルを作ってもらおう。
今回はKaggleのチュートリアル的コンペである「タイタニックの生存者予測モデル」を作ってみることにする。
これは多くの方が慣れ親しんだものであるし、一般的にはスコア0.75で平均点くらい、0.8を超えればまあGoodだよね、という理解があったものなので、客観的にどのくらいのレベルなのかわかりやすいだろうと思ってのことだ。
なお、生成AIはMicrosoftのCopilotを使用した。
GPTでもGeminiでもよかったのだが、今回は記事の趣旨から「課金しない(完全無料)」で「添付ファイルを読み込める」ことを条件に選択させていただいた。
ほんとに簡単な指示で平均レベルのコードは作れる
まずは小手調べとして、簡単に指示を出してみよう。
「train.csvファイルを分析し、survivedを予測するモデルを作成して欲しい。」これだけである。
5秒ほどで出てきたコードが下記だ。
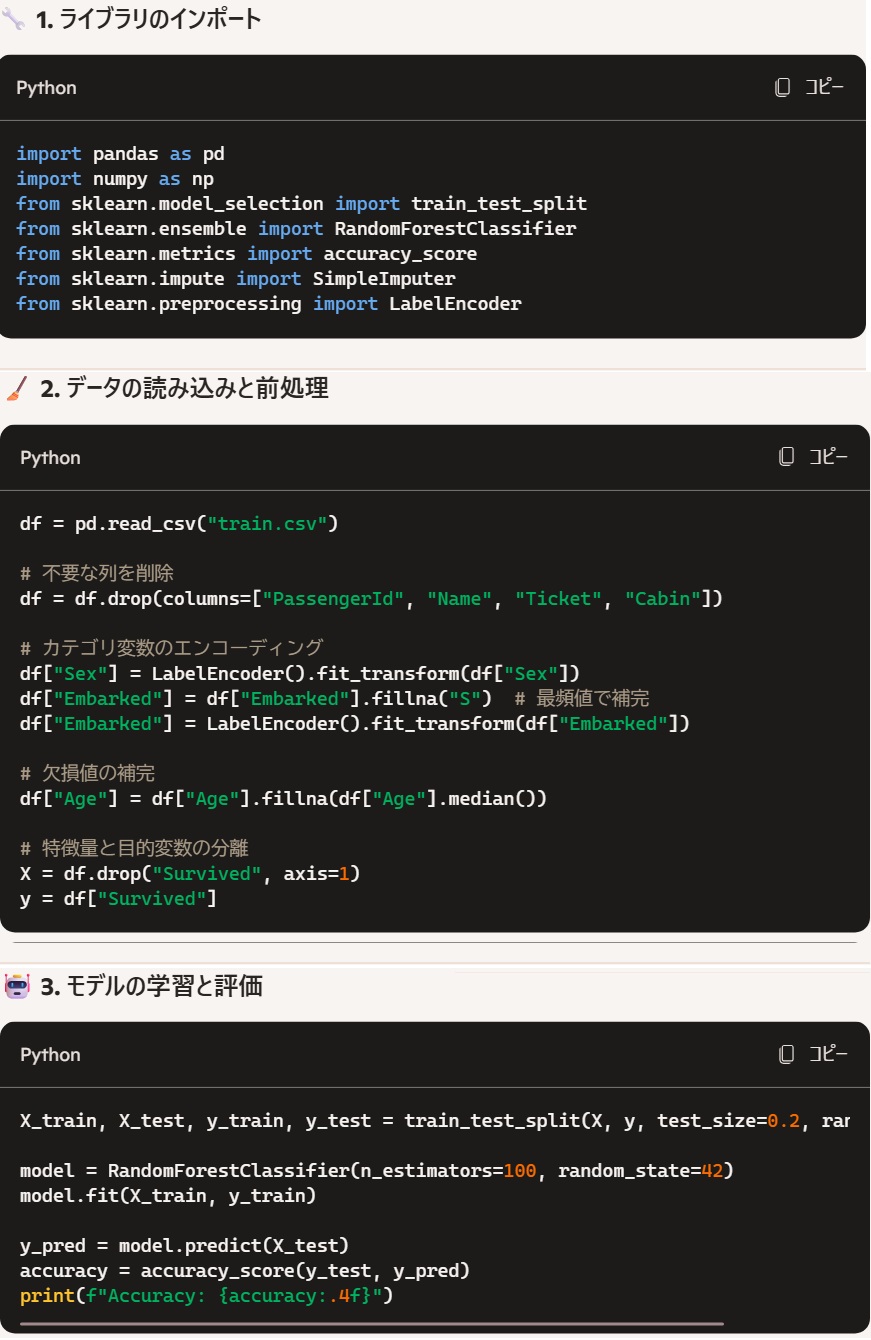
こちらから前処理や特徴量の指示はしていないが、乗客番号や乗客名は予測に無関係として勝手に削除してくれた。またアルゴリズムも同様に何も指定していないが、みずからランダムフォレストを選択してくれたようだ。
タイタニック問題は決定木系のアルゴリズムが適していることが広く知られており、その点きちんとおさえて選択してくれたのだろう。ただ、その昔はKNNとか他の手法を色々試している人もいたわけだし、そちらに引っ張られずにちゃんと選択してくれたのは偉い。
それでは次に、こちらのモデルでtestデータを予測し、その結果を出力してもらおう。
これも5秒ほどでコードを作ってくれた。
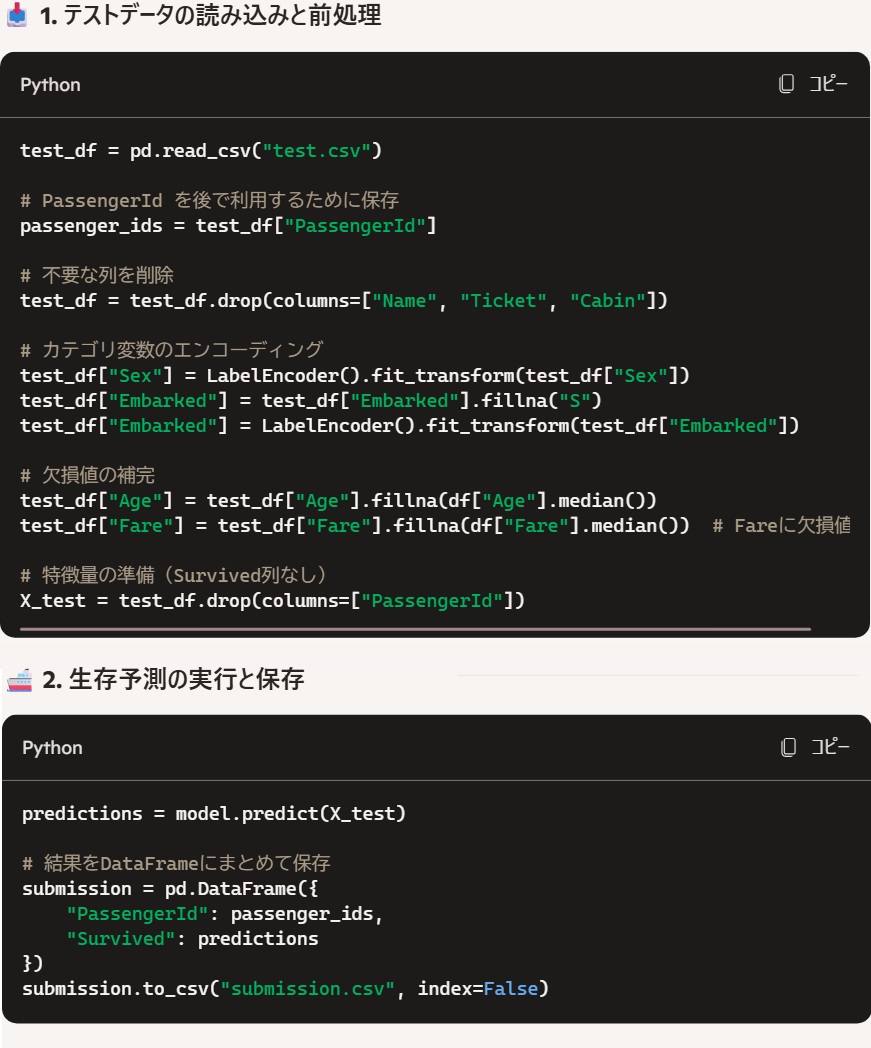
こちらのコードも、特段の問題はなさそうだ。
まあ、Kaggleに提出するにはファイルパスが間違っているなどのご愛嬌はあれど、ほぼコピペで提出してもエラーはなさそうなクオリティだ。
そこで、実際に試してみることにする。
上記の生成AIが作成してくれたコードをコピーし、KaggleのNotebook上で実行してみよう。問題なく処理され、submission.csvが提出された。
スコアは「平均点以上ではあるがGoodには及ばず」といったところだが、こちらから一切指示を出していない中で見事であろう。なにより、作業を始めてここまで1分くらいしかたっていない。
ほんの(?)5-6年ほど前まで、もし初学者がタイタニック問題の予測モデルを作って提出しようとすれば何時間も勉強しなければ難しかった。しかし今はご覧の通りであり、時代の大きな進歩を実感するには十分である。
生成AIとパラメータチューニングしてみよう
とりあえずカタチにできることはわかったので、次に最適化やレベルアップを目指してみよう。
生成AIがみずからXGBoostの使用を提案してきたので、ならばとこの提案にのって上記同様にモデルを作成しKaggleに提出してみることにした。また、Optunaによるパラメータの最適化も推奨してきたので、こちらも合わせて実行してみることにする。
(※ ちなみにOptunaとは、日本のPrefferdNetworks社が開発した最適なハイパーパラメータを自動探索する為のフレームワークである)
最適化は人からの指示やサポートがないと難しい
XGBoostの使用もOptunaの使用も違和感はないが、残念ながら作られたコードはいくつかエラーが起きてしまうものであった。とはいえそのエラーは列ラベルの欠損や列型の問題といった軽いもので、生成AIがみずからエラーを説明&修正することで読み込めるレベルのものであった。
Optunaも、試行回数等は初期設定ながらきちんと動作している。
と、ここまで作業の流れとしては良かったのだが、しかし小一時間ほど上記を中心とした生成AIの指示に従ってフィッティングした結果、最終的には生成AIの指示に従うだけでは、最初のモデルのスコアを超えることはできなかったことを付記しておく。
この理由としては、おそらく過学習気味になったことと、そもそも本来はパラメータチューニングよりも前処理(特徴量エンジ)の方が影響力が強いことがあるだろうが、さすがに最初からそこまで見越したコードは書いてくれなかったというわけである。
なお特徴量エンジに関しては、SHAPを使って寄与度を見える化することは提案してくれるし、そのためのコードも書いてくれる。しかしそれを見て何をするか判断するのは、まだ人がやらねばならないなと感じるものであった。
おわりに - 生成AI時代の"AI人材"とは -
今回の記事では、生成AIだけを使って予測モデルは作れるのか、実際に試した結果を共有している。
タイタニック問題はその予測モデル含めあまりに有名であるため、企業の課題分析にも同じレベルで生成AIが使えるかはアナザーストーリーである。
また、ほぼコピペでOKといっても、ファイルパスにファイル名・パラメータ数値などご愛嬌的な間違えは必ず起きるだろうし、本当の未経験者であればそもそもどこにコピペすればいいかわからないものだ。だから、今後も人がPythonやRをまったく知らないでいいということにはならないだろう。
しかしそれでも、「Pythonのコーディング」というものの労力やハードルは大きく下げられる時代になったのではないかと思う。
一方で、データに対し「問い」を立て、処理を工夫し、パラメータを調整して最適化していく作業は人に求められるクリエイティビティであると感じた。実際、生成AIは平均点には1分で辿り着いたが、そこからのレベルアップは1時間近くかけてもできなかった。
「問いを立てる」「考えて工夫して最適化する」ことは、もうしばらく専門家=人間の領分になるだろう。
当団体では、企業のAI活用が本格化する黎明期から「AIはコーディングよりも、活用の仕方を考えられる人材が重要」と考え、プログラミングスキルに偏重したAI人材育成に警鐘を鳴らしてきた。
そして、この考えには多くの方がご賛同いただき、AIを使いこなす人材の為の資格試験や法人研修を運営することができてきた。
そしていま、奇しくも生成AIの進歩によって我々の考えが正しかったことが示されてきたと思っている。
もしも万一、本記事を読まれた企業担当者の中にプログラマー育成=AI人材育成と考えている方がいらっしゃるなら、ぜひこれを機に企業で育てるべきAI人材をしっかり再定義していただきたいと思う。
これからの時代を創るビジネスパーソンの皆様には、AIとコーディングの速度を競うのではなく、ぜひAIのコーディング力を使ってどんな問いを・どうやって解くか?を考えられる人材になってもらいたい。
そのためにお役に立てるならば、当団体の資格試験やテキスト、法人研修も活用いただければ幸いである。



